今すぐ自動化すべき時間のかかるIT業務10選!
July 21, 2021

IT自動化はしばしば「複雑で、リソースや多額の投資を必要とするもの」として懸念されがちです。しかし、その解決策は意外にもシンプルです。まずは小さな一歩から始め、繰り返しのタスクを自動化して早期に成果を出すことで、自信をつけながら、より複雑なプロセスへと段階的に拡張していくことができます。
多くのIT部門では、これまでも段階的に自動化を進めてきましたが、サービスオーケストレーション、認知的自律運用、人工知能(AI)といった高度な自動化機能を最大限に活用できる成熟度に達している例はごくわずかです。その結果、企業は自動化がもたらす本来のビジネス価値を十分に引き出せていません。
パラマトリックスのDRIFtプラットフォームは、インフラ自動化の真の価値を最大限に活用できるエンドツーエンドのシームレスな手段を提供します。これにより、クライアントは業務効率の向上、コスト削減、品質改善、新たなビジネス機会の創出、そしてデジタルトランスフォーメーションの加速を、確実かつ管理された形で実現できます。
DRIFtは、ITSMシステム、エレメントマネージャー、モニタリングシステムなどのITおよびセキュリティソリューションとサービスに対応した統合パックを備え、異なるシステムやアプリケーションを横断する包括的なワークフロー自動化を拡張・統一します。
パラマトリックスは、お客様の自動化ジャーニーのあらゆる段階を支援します。初期のランブックオートメーションから、プロセス自動化、さらには自律運用、認知的自律運用、AI活用といった高度な自動化能力に至るまで、革新的なソリューションとサービスを通じて、IT環境全体を自動化し、デジタル企業としてのビジネス成果を実現へと導きます。
サービス提供内容
パラマトリックスは、クラウドインフラストラクチャサービスの自動化に関する以下の機能とリソースを提供しています:
- 既存ITプロセスの自動化最適化サービス:パラマトリックスは、従来の幅広いITタスクやプロセスの自動化を支援します。
- デジタル化戦略の立案と実行支援:パラマトリックスは、クラウドインフラストラクチャ自動化に関するコンサルティングおよび実装サービスを提供し、ロードマップの策定から、インテリジェンスを備えた自動化のためのツール・技術・専門知識を提供します。
- DRIFtオートメーション・リファレンスアーキテクチャ:パラマトリックスおよび世界的パートナーの統合技術により構成された、統合型・モジュール型・多層構造の自動化プラットフォームで、すべてのサービスを支えます。
パラマトリックスの強み
お客様の自動化および自律運用の成熟度がどの段階であっても、パラマトリックスは現在のビジネス目標の達成を支援し、新たな技術の進化を最大限に活用できる体制を提供します。
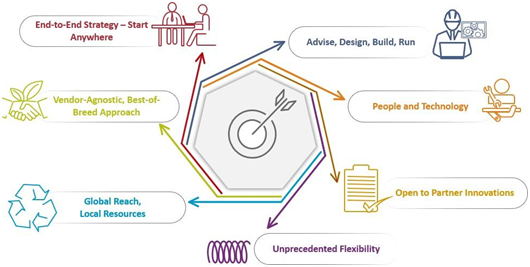
- エンドツーエンドの対応力:初期段階からでも、クラウドインフラストラクチャ自動化の全工程を通じて包括的に支援します。
- ベンダーロックインなしのベストプラクティス型アプローチ:Automation Anywhere、UiPath、Roboworx、Microsoft、VMwareなど、世界有数のエコシステムパートナーによる最適技術を統合し、柔軟に導入できます。
- 統合型インフラサービス:自動化機能を補完・強化し、さらなる価値を提供するインフラサービスを実装します。
- 比類なき柔軟性:必要な個別サービスを選択しても、将来的にサイロ化や非互換が生じる心配はありません。組み合わせも自由、オンプレミス・クラウドの両展開に対応し、コスト最適化にも寄与します。既存技術との連携にも柔軟に対応可能です。
- 「何を」「どうやって」までサポート:業務目標達成のために自動化すべきポイントと、それをどう構築・運用すべきかを、技術面だけでなく「人・プロセス」も含めて包括的に支援・実行します。
- グローバル対応・ローカル展開:世界中どこでもサービス提供が可能。ニーズに応じてスケールアップも容易です。
- 将来を見据えたテクノロジー対応:当面の目標を支援するとともに、新たな技術やソリューションの導入にも柔軟に対応し、変化に強い基盤を構築します。
1. パスワードリセット/アカウントロック解除/パスワード変更
貴社のITチーム(およびヘルプデスク)は、Active Directoryのパスワードリセットやアカウントロックの対応にどれほどの時間を費やしていますか?企業の規模やユーザーからのリクエスト数によっては、週あたり数十時間にのぼることもあります。
複雑なパスワードポリシーと頻繁なパスワード変更が重なることで、アカウントロックの再発が多発します。
一部のITサポートスタッフでは、1日の業務の約40%をパスワードリセット対応に割いているケースもあります。
各リセット対応には、電話認証、リセット実行、確認、通話記録などの手順が含まれます。
このプロセスを自動化するだけで、ヘルプデスクへの問い合わせを30%以上削減できます。
DRIFtによる自動化:
DRIFtを活用した自動ワークフローが、パスワードリセットやアカウントロック解除の一連の作業を処理します。ユーザーはセルフサービスポータルからリクエストを送信し、ワークフローが自動で処理。必要に応じてSMSによるスタッフの確認を挟むことも可能です。
この仕組みにより、サポート対応数の削減とユーザーのダウンタイム短縮が実現。管理者はユーザー操作の可視化・制御ができ、より価値ある業務に集中できます。
2. サーバーディスク容量の確保
アプリケーションの予期しないダウンタイムの原因として最も多いのが、ディスク容量の逼迫です。特にSQLサーバー、IISアプリケーション、Exchangeなどでディスク不足が発生すると、ネットワーク障害よりも大きな影響を及ぼすことがあります。
たとえば急激に増加するログファイルの放置によって、サーバーがクラッシュする可能性もあります。些細に見えるこの問題が放置されると、高額な損失と長時間のダウンタイムにつながるリスクがあります。
ディスク容量管理はすべてのIT担当者の重要課題であるにも関わらず、いまだに多くの障害の根本原因となっています。
監視やディスククリーンアップの定期実行といった作業は、繰り返し発生する時間のかかるタスクです。これを自動化すれば、担当者の負荷を大幅に軽減できます。
DRIFtによる自動化:
- サーバーのディスク容量を常時監視
- ログファイルや一時ファイルのアーカイブ、削除、または別の場所への移動を自動化
- ディスク容量が閾値に達した際に通知
- スケジュール実行または条件に応じたトリガーで自動実行可能
- DRIFtのワークフローがサーバーのディスク容量を監視
- ログや一時ファイルをアーカイブ、削除、または別の場所へ移動
- ディスク容量に関する通知を自動送信
- 定期的なスケジュール実行、またはトリガーに応じて実行可能
3. リモートPCのシャットダウン
「脱炭素」や「グリーンIT」が社会的な潮流であるか否かに関わらず、エネルギー消費を削減し、IT運用コストを下げるためのシンプルな対策があります。
米国の自動車メーカーFordによると、世界中の従業員の約60%が業務終了後にPCをシャットダウンしていませんでした。
すべてのPCを確実にシャットダウンすれば、年間16,000~25,000トンのCO₂削減と、120万ドルのエネルギーコスト削減が可能だと報告されています。
PC1台あたりの年間節電効果は約36ドル。チリも積もれば大きなコストインパクトです。
DRIFtによる省エネ自動化:
ネットワークに接続されているアイドル状態のPCやサーバーを、あらかじめ設定されたルールやポリシーに従ってスタンバイモードに移行させるワークフローを構築。強制シャットダウンではなくスタンバイ移行を採用することで、起動時の待機時間やトラブルを回避できます。
4. ファイル/フォルダの監視
「変化」は世界にとっては前向きなことですが、システム管理者にとっては必ずしも歓迎されるものとは限りません。
ユーザーがファイルを削除・変更したにもかかわらず、「自分じゃない」と主張する場面に遭遇したことはありませんか?
そのようなトラブルを未然に防ぐためには、ファイルやフォルダの変更履歴や整合性をしっかりと監視することが必要です。それは単に業務上の信頼性の問題だけでなく、セキュリティやコンプライアンスの観点からも重要です。
変更が「起きたこと」を知ることと、「誰が起こしたか」を把握することの両方が不可欠です。
DRIFtによる自動化:
ミッションクリティカルなファイル/フォルダに対して、あらかじめ定義されたワークフローにより以下の作業を自動化します:
- ファイルの変更・削除・サイズ変更・最終更新日時を監視
- ファイル内容のパースおよびデータ整合性チェック
- 変更やエラー発生時に自動でアラートを送信し、対応タスクを実行
- システムの可用性維持のために、ファイルの削除・移動・アーカイブ・圧縮などを自動処理
5. サービスのリモート再起動
アプリケーションの設定ファイルの頻繁な変更、サービスのクラッシュ、メモリ解放の必要性などで、1日に何度もサービスをリモートで再起動していませんか?
バックアップやメールサービスなどが、ちょうど休憩中やプライベートな時間に限って停止するという経験をお持ちではないでしょうか。サーバーへリモート接続して、再起動し、サービスの状態を確認する——こうした作業には時間がかかります。
DRIFtによる自動化:
アラートトリガーまたはスケジュールベースで実行されるワークフローを構築することで、以下の自動処理が可能です:
- Windows/Linuxのサービス、バックアップ、アンチウイルス、スプーラー、メール、アプリケーションサービスの監視
- イベントの診断とトラブルシューティング
- サービス停止時のアラート通知(メール、SMS)
- 自動または半自動の修復処理(自動で再起動、または人の判断を待って再開)
6. SQLクエリの自動実行と結果のメール送信
IT部門や業務用のデータを取得するために、繰り返しSQLクエリを実行して、結果をメールで送っていませんか?
このプロセスを自動化できたら便利だと思いませんか?
DBAやIT担当者が単純作業で手間を取られる代わりに、必要なデータを高速で提供し、ユーザー自身でもデータを取得できる仕組みを構築できます。
DRIFtによる自動化:
自動ワークフローがSQLデータベースに接続し、データを取得してテキストやExcel形式に変換し、指定されたユーザーにメールまたはSMSで送信します。
エラー時には管理者にメール通知。定期的なスケジュール実行にも、ユーザーからのオンデマンドリクエスト(メールやSMS)にも対応。DBAなどの専門スキルは不要です。
7. サービス管理アカウントのパスワード変更
Windowsサービスで使われるドメイン管理者アカウントのパスワード、定期的に手動で変更していませんか?
多くのWindowsサーバーでは、共有のドメイン管理者アカウントがアプリケーション実行に使用されています。
セキュリティ規制やベストプラクティスでは、これらのアカウントパスワードは30日~90日ごとに変更することが推奨されています。
通常、各サーバーで各サービスごとに手動で更新が必要であり、その間はサービスが停止します。平均で1サーバーあたり20分程度の作業が必要となります。
DRIFtによる自動化:
- サーバーおよびサービスの一覧をテキストファイル、CMDB、または他のインベントリから抽出
- 各サービスのログオンアカウントパスワードを自動で変更
- 必要に応じてサービスを再起動
- 処理内容を記録し、レポートを生成
- 変更の成否を通知(成功・失敗のログ付き)
8. Windowsイベントログの監視
企業に損失を与えるセキュリティイベントのうち、少なくとも70%は内部ユーザーが関与しているという事実をご存じでしょうか。
Windowsシステムは、稼働中に常にログを生成しており、トラブルが発生した場合、その痕跡はイベントログに残されている可能性が高いです。
しかし、すべてのWindowsイベントログを手動で追跡・調査するのは非常に手間がかかります。
イベントログを監視すれば、セキュリティ脅威やシステム/アプリケーション障害を迅速に検出できるだけでなく、監査レポートの作成によって、過去の事象の追跡にも大いに役立ちます。
DRIFtによる自動化:Windowsのイベントログ(アプリケーション、セキュリティ、システムなど)を解析し、Exchange、IIS、MS-SQLなどのミッションクリティカルなアプリケーションに関する重大なイベントを自動で通知するワークフローです。
アラートをトリガーとして、即時対応可能な担当者に通知が送信されます。
すべての処理ステップは記録され、後の調査や統計レポート作成にも活用できます。
なお、このプロセスはエージェントをインストールする必要はなく、対象のリモートサーバーでWMIを許可するだけで実行可能です。
9. VMwareタスクの自動化 – スナップショット作成
スクリプトツールを使ってVMwareのタスクを自動化することは可能ですが、高度な専門スキルが求められます。たとえば、VMのプロビジョニング、展開、スナップショットの作成などは、想像以上に複雑です。
VMスナップショットは、ある時点のVMディスクファイル(VMDK)を保存し、万が一の障害時にその時点へ復元できる「保険」のようなものです。アプリケーションやサーバーのアップグレード・パッチ適用時には、まさに命綱となります。
まずはスナップショットのポリシーを策定し、自動でスナップショットを作成・削除するプロセスを設計しましょう。スナップショットはVMと同一のボリュームに保存されるため、容量不足のリスクもあります。古いスナップショットの監視と削除が重要です。
DRIFtによる自動化:
バックアップポリシーに従ってトリガーされるワークフローが以下を実行します:
- 対象VMのリストを読み取り
- 指定された各VMに対しスナップショットを作成
- 古いスナップショットを削除して空き容量を確保(VMwareのベストプラクティスに準拠)
10. インシデントのエスカレーションプロセス
朝7時、IT部門の電話が鳴り止まない。メールシステムがダウンしており、CEOから一般社員まで「問題がある」と連絡してきます。
モニタリングシステムのおかげで、IT部門は問題をすでに検知していたかもしれませんが、電話の数が問題の深刻さを物語っています。
メールはミッションクリティカルなシステムです。レベル1(L1)のサポートエンジニアがSLA内に復旧できなければ、即座にエスカレーションプロセスを起動する必要があります。
IT部門、ヘルプデスク、NOCチームは、少なくとも重大障害用のエスカレーションフローを持っているべきです。そうでなければ、小さな問題が大規模な障害に発展するリスクがあります。
DRIFtによる自動化:
以下のステップを含む自動化されたワークフローを構築します:
- モニタリングシステムからのアラートを自動取得
- L1担当者に通知し、重大度と優先度を判定。SLA内で解決を試みる
- 未解決の場合、L2へエスカレーション。それでも未解決ならL3へ
- インシデントのループを閉じ、チケットを更新し、関係者に進捗と対応完了を通知